
Stuart Cheshire
Sidney Sussex College
One novel feature is that the flow of information is driven by the network software instead of the application. The application does not make a call to the network software saying: "Transmit this data" (say, a request to the file server) "and put the packet which comes back in reply into this area of memory here."
Instead, the network software places incoming packets into a queue, and then interrupts the application to inform it that there is a packet requiring attention. It may not be able to deal with it immediately (for example if it is still dealing with the previous packet) but it should note its arrival and ensure that it does deal with it soon.
Attached to each packet in the queue is a single bit flag. This is set to tell the application that it is now its turn to transmit data. Only after processing a packet which has the `Your turn next' flag set should it then check to see if it has any data which it wishes to transmit. Even if it does not, it should prepare a minimal packet which just contains the machine's node-number in order to proclaim that "This station is alive and well and is listening to the network." The network software will not transmit anything while waiting for this packet to be constructed, so the application should respond as quickly as possible.
In future the receipt of a packet with the `Your turn next' flag set will be referred to as `Receiving the Token' since the function if performs (granting permission to transmit) is analogous with that of the Token on IBM Token Ring.
The purpose of this is to ensure that no two machines can try to transmit at the same time. In an application such as Bolo, where the map is in fact a replicated data structure of a distributed database, this is important. If two machines were to decide simultaneously that they wish to make a conflicting change to the same square on the map then there could be a problem. If they were to place the instruction to make these changes in a packet in their respective output buffers on a conventional network, then the network software would transmit each packet at some undefined time later, with unpredictable consequences. In this network, the problem cannot arise, because only one application at a time can be presented with the permission to construct a packet. By the time the second machine gets presented with the Token, the change initiated by the first will have been made and it will be clear that the second conflicting change is no longer appropriate, and the machine will not even attempt to make it.
In effect, each machine is being given a small time-slice during which it has exclusive write-access to the whole database. Any legal change which is transmitted onto the network is guaranteed to take place, because there is no way for any other machine to alter the database, so nothing can happen which could cause a legal change to become somehow inappropriate by the time it is received at other machines.
A conventional application, such as a word processor which simply wants to communicate to file servers and print servers, could also run on this network, and should not of course have to deal with this level of complexity. Instead, it can just send packets (whenever it wishes) to an intermediate layer of software which buffers them and passes them on to the network layer when requested.
This mode of operation came about due to the nature of the hardware being used. It requires the constant intervention of software to copy the received data to the output port, which means that if any machine in the ring crashes then the ring is broken and data cannot get through. This is a flaw which is designed out of all commercial networks: they are all supposed to be fail-safe against machine crashes.
This network totally fails if any machine on it crashes. For a game, in which all machines are hopefully running the same reliable program, this is not a problem, but in a general network environment where the machines may be being used for different purposes and may crash or be turned off at any time, this is not acceptable.
Surprisingly however, this apparent deficiency has led to a number of extremely desirable properties.
These features, coupled with the way in which the network mediates in granting, to each machine in turn, exclusive write access to the database for a small time, make a very powerful network system. It also uses the available bandwidth of the hardware extremely efficiently, since no acknowledgements are used because the normal running of the network is so reliable and predictable. All the complication is concentrated in the protocol for restarting after failures, which should be rare. Because the network either fails catastrophically or not at all, the applications do not need to be forever checking for small-scale failures such as the loss of an individual packet.
There is also scope for implementing the algorithm in hardware which would enable it to run much faster. It would remove from the processor the need to deal with the network at a byte-by-byte level, and the hardware could instead transfer the data to memory by DMA and only interrupt the processor at a packet-by-packet level. It could even filter out packets which have no relevance to this station to further decrease the load on the processor. As long as it retained the property that the network is deliberately brought down when the hardware has no memory left to store a packet which it needs to, then the reliability of the network would be maintained. It would also be possible to insulate the network from processor crashes because the hardware could be made more failsafe. If it detected that the processor had crashed and was not responding correctly, then it could remove itself from the ring to allow the network to continue. When the user wished to access the network again, it would be necessary to re-join from scratch.
The scheme also has similarities with `snoopy cache' systems used on multi-processor systems accessing common memory. These are used where each processor caches the parts of memory it is accessing, but must also keep up to date with changes made by other processors. As well as operating a `write through' cache to update changes to the main memory, the caches also `snoop' on the bus and observe writes made by other processors. When a write is made to a location which is currently cached locally, the cache takes the value off the data bus and uses it to update the local copy.
This network implements a slightly more macroscopic version of the same thing, and could be used where a number of workstations are accessing a large central database. Workstations could cache parts of the database locally to improve performance, and when one writes a change to the main database, the others could `snoop' on the network to see if the change affects any data they have cached, and if so use it to keep their local copies up to date. In effect, the same thing is being done in the game, even though there is no central database and the data is distributed and replicated in all the machines.
Thus it was decided to use the serial port. Special cables were made in which the input and output were connected separately to two different wires coming out of the plug, and the two wires had a matching plug & socket on the ends:
Thus the machines were connected up in a ring, and any machine could send a message to any other by labeling the message with an address identifying the recipient, and relying on the software in the other machines in the ring to pass on the packet from machine to machine until it reached its destination[22].
There was concern that there might be a problem if the previous byte had not yet been sent and the register was not yet free to receive another byte. Bytes arrive at regular intervals, but, due to the fact that there must always be some small (and varying) delay before an interrupt is processed, they are not processed at regular intervals. Bytes are therefore not placed in the transmit register at regular intervals, and the interval between bytes being placed there is sometimes more than the time taken to transmit a character, and sometimes less.
For example:
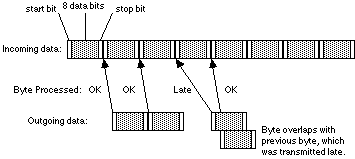
The third byte is processed late, so there is a pause in the transmitted data before it. The fourth is processed on time, but the third is still being transmitted so the serial port is not yet free.
Fortunately, this is not quite the way the serial port works. There are actually four registers. Two are serial shift registers, to send and receive data from the outside world, and two are parallel registers, to communicate with the processor via the data bus.
Incoming bits are placed into the shift register. When a character is complete and the framing is correct[24], it is transferred to the Receive Data Register and an interrupt is signalled. The processor then has one character's worth of time[25] to fetch the character from the register before the next one (currently arriving at the shift register) is completed and transferred into it.
A similar process occurs on the transmitting side. When the first byte is written to the parallel register, it is immediately transferred to the shift register and transmission begins. A second byte can be placed in the parallel register and it will be held there until it is needed. Then, when the shift register becomes empty the byte is transferred across and transmission continues uninterrupted. An interrupt is signalled and the processor then has one character's worth of time to load the parallel register so that it will be ready for when the shift register needs it. Unlike the input register, this is not critical, and if it does not do it on time, then the shift register will just wait until the next character is provided. No error condition will be generated, but of course the serial port will not be transmitting data as fast as it could be[26].
So, in fact, the following occurs:
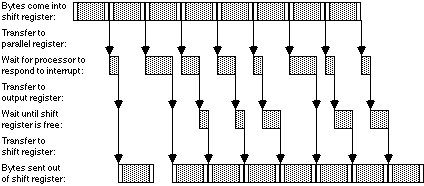
Receive interrupts are occasionally processed late, resulting in brief pauses in the output. They can never be a whole character time late (or an overrun error will occur), and for safety, they should not get too close to this time. The time lost in those brief pauses can never be caught up again, for even if further output characters are transmitted end-to-end without a single pause, the best we can hope for is to just keep pace with the input and not get any later than we already are[27]. Let us assume that interrupts may be disabled for up to, but never more than, half a character time. Then all output will eventually end up half a character late, because once one byte has been processed and sent half a character late (due to a slow interrupt), all following bytes can only be sent in turn after that one, so they will all be half a character late.
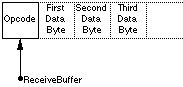
A fixed location was used because the 6502 does not allow efficient use of pointers. To receive bytes as fast as possible under interrupts without having to save the X and Y registers, the following method was used:
LDA &FE08:LSRA:BCC NotAReceivedByte
.putbyte:STA ReceiveBuffer:INC putbyte+1
Receivebuffer was placed on a page boundary[29] so that no carry to the high byte could occur, so only a one-byte increment would be needed. Being on a page boundary, the low byte was equal to the number of bytes received, so it was very easy to check if the whole opcode had been received yet:
LDA putbyte+1:CMP opcodelength:BEQ execute:LDA&FC[30]:RTI
As you can see, this was indeed very fast, taking only 9 machine instructions to receive the byte, but it is now clear that the worry about speed was not necessary because an interrupt routine can take much longer than that before it begins to impinge upon the performance of foreground routines.
After the last byte had been read, the appropriate routine would be called, which would read the data from the fixed memory location and perform the required action.
Each player would begin by transmitting the `New Player' opcode, which would set a variable curplayer to the player number in question, and all further opcodes could be assumed to have come from that player until another `New Player' was received. Opcodes setting the coordinates of the tank, shells fired, mines exploded etc. would then be sent, and finally an `Over to You' opcode telling the next machine to start sending its data. This was a single byte opcode (no data bytes) with value &FF. This was so it could be easily recognized by the ring software and not transmitted on the the next machine in the ring (which would have obviously disastrous consequences). The recipient of `Over to You' would then send a `New Player' opcode stating his player number and follow it with whatever opcodes were necessary, before sending an `Over to You' on to the next player.
This had several drawbacks:
(i) The opcode had to be executed fast, with interrupts disabled, otherwise the next opcode could start arriving and overwriting the fixed storage locations containing the data.
(ii) It was inefficient to preserve registers and certain locations of global variables (by pushing them onto the stack) when most of the time only a relatively short, simple, trivial operation was to be performed.
(iii) There was no error checking, for to add a CRC[31] check to every opcode (often only a single byte) would have crippled the performance of the network.
(iv) It was noticed that every group of opcodes sent by a machine started with a `New Player', followed by a tank direction opcode and a tank location opcode. Since every machine knew that these opcodes were due to arrive, in that order, it seemed a waste to actually use a valuable byte of network space to say so. Hence, it could be assumed that `New Player' was going to be followed by the tank's direction and position without actually sending a separate opcode byte for each one. In other words, all that data was being incorporated into the `New Player' opcode itself. It was the extension of this into its logical conclusion which led to the scheme described below.
The &FF `Over to You' opcode was altered too, because it is necessary that the recipient of this opcode removes it from the ring and does not pass it on to the the next machine. When all the opcodes were separate, it was easy just to not pass on this opcode to the next machine round the ring. Now that they are buried inside a layer of protocol -- the packets -- it would be very difficult to extract the `Over' opcode as the packet went past.
Instead a kind of `token'[33] was devised, which was a separate packet. It was a special packet, one byte long, just containing the value &00. Since every packet is supposed to begin with its length, in bytes, &00 is obviously an illegal value. This meant that is could be safely used as a `token' which has a special meaning, because it could never occur normally at the start of a new packet.
The packet was still read into fixed workspace but the speed pressure was taken off because of the arrangement of the data in the packet:

As soon as the final byte had been received the network driver called the network module of the program. Interrupts are left disabled, because a new packet will will be following on shortly, and it must not be allowed to overwrite the start of this packet until we have read the data out of it.
First, the CRC was checked, and the packet was rejected if it failed.
Since the &FF `over' opcode was no longer needed (because the purpose it previously fulfilled was now performed by the Token instead) its meaning had been altered to mean `end of packet'. Using the length byte to indicate where to put it, the packet was delimited by placing an &FF after the last byte.
The player number was copied to curplayer.
The position of the tank was stored in the enemy table and, using the direction data, its character in the object list was updated (new character if it had changed direction, new position if it had moved).
You will see that the first 7 bytes of the packet have now been dealt with and are no longer required. This means that interrupts can now be re-enabled, and even if there is a byte waiting on the serial port (and there probably will be by now) it can overwrite the first byte of the packet without any ill effects.
Because it is likely to take a significant time to deal with all the data in the packet, interrupts must be re-enabled or bytes arriving on the serial port will be lost. Unfortunately, this means that incoming bytes will be overwriting the data in the fixed buffer, so they will be `chasing' the execution routine through memory and if they ever overtake it then they will destroy the data it is trying to use.
Fortunately, the first 7 bytes of the packet have been dealt with already so 7 bytes can be received before we start losing data which still needs to be processed. Because the packet processing routine runs through the packet executing opcodes much faster than they are received on the serial port, there is not even the slightest risk of the new packet catching up with the old one and overwriting unprocessed data.
The slowest opcode to execute was the message opcode, because it involved scrolling the message line one character to the left and drawing the new character at the right-hand end. The message line was 37 characters long, made up of 2368[34] pixels. To scroll this line and print the character took about 5ms[35].
The opcode consisted of 3 bytes: opcode, recipient, 1 character of message, This took 6ms to receive at 4800 baud -- longer than it took to execute.
It would even have been acceptable if some opcodes had taken longer to execute than they did to be received, because they could have taken advantage of the 7-byte head start, as well as the extra gain made by the other, quicker, opcodes.
Unfortunately, in the above scheme this is not guaranteed.
Suppose: A sends a very long packet, and, while it is being executed, B sends a very short packet. This overwrites the start of A's packet of course, but this is not a problem because the execution of A's packet is well past this point by now, but it is not yet completely finished. Being such a long packet, there are more opcodes right at the end still to be executed. Execution of B's packet must start immediately or it will be overwritten by C's following immediately afterwards. This is exactly what happens -- on receiving the last byte, the network routine calls the execute routine and B's packet is executed.
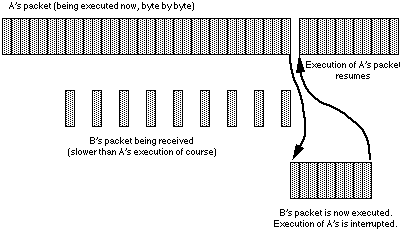
Fortunately the execution routine is re-entrant and all necessary global workspace is preserved, but an important principle has been violated -- the data in B's packet was processed before all the data in A's had been. We don't know how far through the execution of A's packet the processor was when it was interrupted, so we don't know which opcodes of A were executed before the opcodes of B, and which after. In fact it will vary on each machine in the ring, depending on how heavy the interrupt loading from other sources is. So not only do we not know the precise order of execution, but it may be different on different machines. This means that in the example above, we wouldn't know which had been performed later -- the building of the road or the building, so we won't know which one got overwritten and which one remained[37].
The obvious solution was to use a circular buffer for incoming packets. The reason it took so long to make this decision was the amount of code which had to be re-written. While the program was being regarded as just an experiment it always seemed easier to fix individual bugs as they appeared than to alter fundamentally the way in which it worked. Hence the program evolved slowly from the original `opcode' approach, with small changes and refinements along the way. Whenever timing problems occurred, they were tackled individually by rewriting the appropriate routines to make them faster, instead of questioning the basic principle which made timing a problem in the first place.
This solution was actually discovered while doing the conversion to the Macintosh. In order to get a version working as quickly as possible, it was decided to use the standard serial port driver on the Macintosh instead of writing interrupt routines in 68000 assembler to drive the hardware directly.
An input buffer of 4K was allocated -- long enough to accommodate a maximum length packet (256 bytes) from every player. The intention was then to call a polling routine frequently to process the received data. Packets might be executed a little late, but this would have no adverse effects. Only when the Token arrived would the delay before the program responded have any adverse effect. Since, for the purposes of development, there would be only one Macintosh in a ring with 3 BBCs, the slowing down would not be so serious. Of course, when the program is finished, it must perform as fast as possible by receiving packets under interrupts, but this was not essential in order to get a simple version working.
It was then realized that this technique was also applicable to the BBC micro, and would take a lot of the timing pressure off.
Using a circular buffer means that however fast a packet arrives from the network, it cannot overwrite the one being executed because it is being placed after the existing packet, not on top of it.
It also means that execution of this packet does not need to start immediately, because it can be safely left lying in memory, knowing that it too will not be overwritten either, because the next packet will be arriving after that one in memory, and so on.
This also solves another problem. Because packets had to be executed immediately they arrived, there was no way to lock a data structure (such as the screen object list) for exclusive access by a foreground routine, because a packet might arrive (which must be executed immediately) which causes a new character to be created (ie. inserted into the list). The only way to do this was to disable interrupts, which could only be done for a very short time (or bytes from the serial port would be lost).
Now, it is possible to set an `execution critical' flag -- a lock -- which still allows bytes to be received under interrupts, but inhibits actual execution of packets until it is cleared. At 4800 baud, with a circular buffer of 256 bytes, execution can be postponed for about 1/2 a second before packets begin to be overwritten -- more time than any routine could ever reasonably want a data structure to be locked for.
It was therefore vital that the network should detect and recover from these errors.
The handshaking lines of the serial port are used to indicate when some kind of error (Network `Failure') has occurred. When a machine sees the the CTS line go high, it abandons all transmission, and invokes the error routine. This is consistent with the conventional use -- to suspend transmission because the buffers at the receiving end are becoming too full[38].
Note the following terminology:
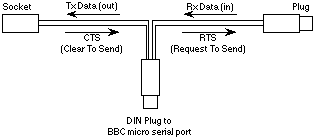
Notice also, that the flow of information along the handshaking wires is in the opposite direction to the flow of data around the ring. In the above diagram, imagine that the ring is broken immediately to the left. Transmitted information cannot now get through to the next machine, but the error indication, assuming that this is the only break, will get all the way round the ring in the other direction.
The names of the handshaking lines are easy to confuse because the functions are symmetrical. It not obvious whether the line called `Request To Send' is the one with which you request that the other machine send data to you, or the one on which you receive the request to send data to the other machine. Likewise, it is not possible to just guess whether CTS is for telling the other machine that it is clear to send data to you, or for telling you that you are clear to send data to it. It may be helpful to remember that the RTS line controls the Receiving of data. If in doubt, refer to the diagram.
Remember also: The RTS line is low for normal receiving of data, and is driven high to halt it.
There are several causes of `Failure':
After transmitting a packet, a machine keeps a copy until the packet has come all the way round the ring has been received again[39], in case the packet gets lost and has to be retransmitted. When a failure occurs, any packets which have been in the circular buffer for more than a very short time will probably have been disposed of by their senders because they thought they knew that everyone had received a copy. Hence, they must be executed before the failure routine is invoked. The packet which is in the process of being received obviously cannot be executed, and must be thrown away, but this is quite safe because we know definitely that it has not gone all the way around the ring back to the sender, so the sender will not have disposed of it and will retransmit it when the network resumes.
Now, instead of immediately calling failure, the error flag is set, to cause incoming bytes to be ignored, and not stored or relayed on to the next machine. Execution of packets continues, and after the last one has been executed, the error flag is then checked routinely, and when found to be set, the failure routine is called.
When called, for any of the above reasons, failure does the following:
(i) It drives RTS high. If the error occurred here, then this is telling everyone else that an error occurred. If the failure was caused by seeing CTS go high, then this is simply passing that information on round the ring to everyone else.
(ii) It waits until is sees CTS go high. If the failure was initiated here, then this is to wait until everyone has acknowledged the failure. If the failure was received from someone else on the CTS line in the first place, then this `wait' will obviously not take very long.
(iii) It then goes into a loop, transmitting a byte repeatedly. This byte is &FF if this machine was transmitting when the ring failed, or still has an unconfirmed packet which it wishes to retransmit, and &00 if it does not with to retransmit. Thus, if in a ring we have 16 stations, imagine: Station A has transmitted a packet which it is halfway through receiving back. Station B transmitted a packet after that, which it hasn't started getting back at all yet. Station C has just started sending its packet and is halfway through transmission:
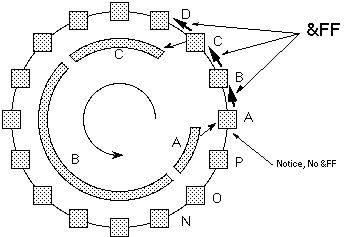
According to the above rules, after the failure, A, B and C will all be transmitting &FF, and all other stations will be transmitting &00.
(iv) All stations which wish to transmit wait until they receive 20 zeroes. The reason it is 20 zeroes is to ensure that a single spurious zero could not cause a false restart attempt. Since this is likely to be running in unreliable circumstances (remember, an error just occurred for some reason) this is sensible. Of course, C will be receiving &FFs from B, and B will be receiving &FFs from A, so A is the only station which will be receiving zeroes[40]. It responds by doing an active restart. This means, it drives RTS low again to indicate that the error is over. Other machines seeing this drive their RTS lines low too (see below). Station A waits for 1 second for the change to be propagated all the way round the ring and come back into its CTS line, and if it does not (because the ring is still physically broken somewhere) then it gives up and re-enters the main wait-for-zeroes loop. If it does come back, then A pauses for another 4 ms to give all stations time to get ready, and then it initiates transmission of the packet and exits the failure routine.
This mechanism relies on at least one station in the ring having nothing to send, and thus communicating zeroes to the next machine to tell it that it is allowed to do the restart. This will always be the case, because there is a two byte delay through each machine, and all packets are longer than this. There is therefore not enough room in the ring for every machine to have a packet in transit which it is waiting to see come back round the ring.
(v) Any station seeing the CTS line go low assumes that this means the network is ready to go again, and responds by doing a passive restart. This means that it drives it RTS line low, to pass on the signal, and then it waits for 2ms to make sure CTS stays low and wasn't just a transient glitch. If it does stay steady, then it re-enables interrupts and exits the failure routine, expecting a packet to begin arriving shortly.
When the retransmission of packets begins, the network code identifies packets it has seen before and does not pass them to the application (the game). They are recognized by two mechanisms.
The way this is done is to use a list of players. When the Token is received, the list is set to the empty list. As each machine's packet is then received, its number is added to the list. If any packet from a player is received a second time then it will be found that its number is already in the list, so it will be rejected. This also means that at the time when the Token arrives again, the machine is in possession of a list of all the machine numbers in the network.
... M, N, O, P, A1, T1, Transmit data, Pause, Failure, Restart, A2, T2 ...
This inability to restart caused considerable worry about the reliability of the Token. It seemed that two machines were both trying to start up the ring -- and obviously clashing with each other.
This is a serious worry, because the corruption of the length byte at the start of a packet, from say &20 to &00, requires the corruption of only a single bit, and the resulting (erroneous) Token is not protected by any CRC check, which might otherwise reject it. This is doubly bad, being the only error the program cannot recover from. Both machines try to start up, and fail, and try again and fail, and the game never restarts. While there is a reliable mechanism for ensuring the integrity of the data within the packet structure, there is no mechanism for ensuring the integrity of the packet structure itself.
What is more, it was realized that the problem of spurious tokens was being invited by transmitting all the &00s and &FFs round the ring during the arbitration for restart, and I suspected that it might be possible that a stray &00 left over could be the cause of the erroneous Token. This problem was remedied by forcing a hardware reset of the serial port before the network resumes operation. The machine nominated to restart transmission first pauses for 1/10 of a second to ensure all of the ports have completed the reset operation before data is sent.
Also, at this time, consideration was being made of the performance implications of the fact that, after receiving the packet from the previous machine, it is one byte-time later before the machine receives the &00 Token, and then it takes some time to generate the new packet, so it may not be transmitted as closely after the preceding packet as it could ideally be. For this reason, the nature of the Token was altered to setting the top bit of the first byte (the length) of the packet. Being the first byte, this is easy to strip off and not send on to the next machine, and it has the advantage that you know at the start of the packet, not after the end, that your turn is next. This means that, in a high performance system, the network module could inform the program via interrupt that the final packet before `our turn' has just started to be received, and the program could begin to do some preliminary work in preparing some of the data for the packet, so that when it is finally called upon to deliver the completed packet, it can do so more quickly.
The implementation of the circular buffer led to a few more changes in associated parts of the program. The two CRC bytes were taken out from inside the packet and moved to the end. This allows different network drivers to add their own levels of error detection and correction, as is felt appropriate according to the reliability of the hardware being used. The mechanism and number of extra bytes used is transparent to the application, which just sees a raw packet containing a length byte followed by the data. A new cause of `Failure' was also added:
A more elegant algorithm would be able to cope with this happening while it worked, but that would have required more memory and in the circumstances the simplest solution was just to lock out all changes while the critical operation was being performed.
setlock(0) means that there is no restriction, and packets can be executed immediately, inside the interrupt routine, as soon as they arrive.
setlock(n) means that packets can be executed, but we would rather that they are not because we are drawing the screen at the moment and we want it to be done as fast as possible to cut down flicker. Packets will not be executed unless the screen has taken an extremely long time to draw and we have more than n bytes waiting in the circular buffer. The exception to this is if we receive a packet from the station just preceding in the ring. It will be our turn to transmit next, so we should get all the pending execution done as soon as possible because otherwise we will hold up the ring. In effect, n is an estimate of the time we expect the task to take, and if it overruns the time allocated, then execution of packets is allowed to resume. It is arguable that n should be given in milliseconds instead of network character times, but this does not take account of the fact that the time which will be taken to deal with the bytes may be as important or more important that the time which was taken to receive them.
setlock(255) means that a critical operation is taking place, so no packets may be executed, whoever they may be from. To avoid slowing the network down, setlock(255) is only used for short lengths of time[42].
The problem is that they must be given an up-to-date copy of the map, and other information concerning the current state of alliances, the locations and current owners of pillboxes and bases etc.
They cannot be simply given all the information at once, for two reasons:
The solution below was arrived at after long and hard experimentation and analysis of many possible alternatives. The algorithm may seem simple, but it took a great deal of effort to discover it. It involves sending the really critical data first, and then sending the map more slowly and keeping it up to date with changes while this is done.
A global flag: joining is set to zero. The program then enters a loop which simply waits until the top bit of joining becomes set, before the machine actually enters the game. While joining < &80, its value alters the way that the interrupt routines react to incoming packets, requests to provide outgoing packets, and failures:
It then transmits a `give me boot data' opcode. All other players, seeing this, set the `boot data required' flag. The first to get the Token after this responds by sending the boot data, and all the others clear the flag when they see that the data is being sent. Because the boot data is over 256 bytes long, some special technique had to be found:
The first boot data packet -- pillbox data -- is sent, but no Token is attached. When this packet comes back round the ring, the machine which sent it treats it like a special kind of Token, and initiates the transmission of the second boot data packet -- the refueling base data. When this comes back, the third boot data packet -- the header of the map data -- is sent, and only then, when this comes back, is the players own normal game-play packet (with Token) sent.
This is a total of &120 bytes and causes a delay in the network of just over 1/2 second[43].
The map structure is set up so that all the row-end coordinates are zero. This table gives the coordinates of the first deep sea square after the map data -- ie. every row is completely empty. This special value is normally used to indicate any empty map row. In addition, the row-start coordinates are set to &FF. This special value is used to indicate that the map row is unknown, and required to be filled in, so it must be requested. If the map row is actually empty, then the row-end entry will remain at zero, to indicate an empty row, but row-start will be set to zero too.
Every write to the map fails because putmapcell believes that it is attempting to write to deep sea, but in all other respects opcodes are executed as normal. As lines are slowly read in, the data is placed somewhere in memory and the map row pointer is set to point at the appropriate address. The start and end coordinates are now set, and subsequent writes to these areas will keep the map up to date while the rest of the data is being sent. When the whole of the map is complete, the game can begin, confident that the whole map is actually up to date.
When a player leaves, any pillboxes continue to be regarded as hostile, if you are not an ally, but minefields must, of necessity, disappear. Only mines which are also stored in allies maps will remain active. It is possible that when using the modem driver module, connected to some central computer coordinating all the stations, that this computer could maintain a global minefield map and use it to preserve absent players minefields. It would also be possible to produce a slightly modified version of the game to run on the ring, to act as a monitor station and perform this task of maintaining a global minefield map.
![]()